
第1章 网络信息获取 - 被动获取
1.1 介绍和概念
被动获取需要管理员授权才能协助访问网络设备; 并且需要很高的实时性,否则会发生丢包。 未经授权的被动信息收集可能是非法的。 被动获取需要解析应用层协议。 在被动信息收集过程中,使用公开的信息收集有关目标的信息。 可以使用搜索引擎结果、谁是信息等。 被动获取需要事先授权,即使用路由器、交换机等需要事先授权。
1.1.1 获取范围
范围有限,因为网络流量流经网络设备,只能捕获网络数据包。
1.1.2 数据处理实时性
将符合过滤规则要求的报文保留。 需要实时数据处理。
1.1.3 技术指标
吞吐量和数据包丢失是主要问题。 可以通过增加吞吐量来减少数据包丢失;可以减少不必要的系统调用以改善数据包捕获。
1.1.4 技术难点
过滤规则的配置和测试很复杂。 过滤规则中的错误可能会暴露于漏洞。 它应该很容易使用新协议进行定制。
1.2 以太网的广播通讯
1.2.1 以太网
在以太网中,所有通信都是广播的。 同一网段上的所有网络接口都可以访问物理介质上传输的所有数据。 每个网络接口都有一个唯一的硬件地址,也就是网卡的
MAC 地址。 大多数系统使用 48 位地址,用于表示网络上的每个设备。
1.2.2 数据的收发
数据的收发是由网卡来完成的
a) 网卡中的单片软件获取数据帧的目的MAC地址,并使用计算机网卡驱动配置的接收方式来判断是否应该接受。
b) 当确定已接收到接收时,会发出中断信号以提醒 CPU。
c) 不应该接收的数据将被关闭,计算机将完全不知情。
d) CPU接收到中断信号,操作系统联系驱动程序接收来自网卡的数据。
e) 驱动程序将接收到的数据放在信号栈上供操作系统处理。
1.2.3 四种接收模式
a) 广播模式:接收网络中的广播信息。
b) 组播模式:接收组播数据。
c) 直接模式:只有目的网卡才能接收数据。
d) 混杂模式:接收所有通过它的数据,不管数据是否发送给它。
1.3 网络数据包捕获技术
网络数据包捕获是在数据链路层增加一个旁路进程,对发送和接收的数据包进行过滤/缓冲,最后直接传递给应用程序。
1.3.1 基于套接字的网络编程
网络通信被视为一个“文件”描述符,对这个“网络文件”的操作类似于普通的文件操作。
1.3.2 数据链路提供者接口(DLPI)
它定义了数据链路层向网络层提供的服务。 它是数据链路服务的提供者和用户之间的标准接口,在实现上基于UNIX流机制。
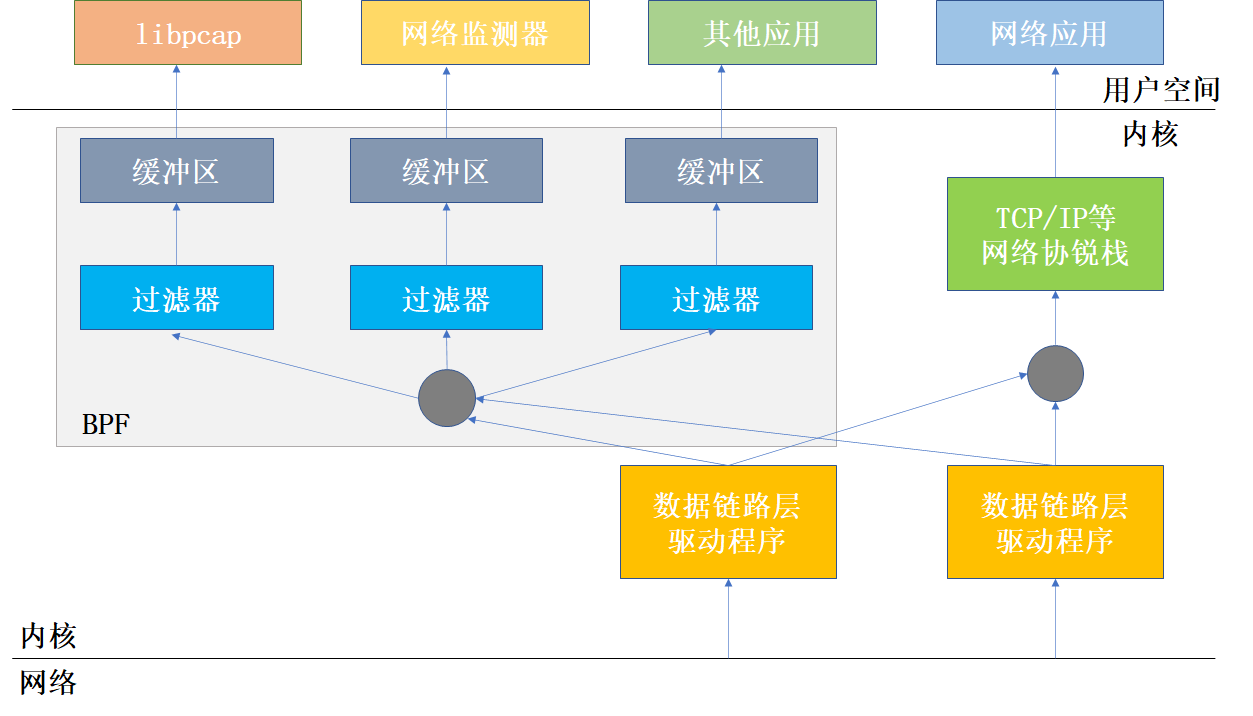
1.3.3 伯克利数据包过滤器(BPF)
BPF是一种高效的数据包捕获机制,工作在操作系统的内核层。 使用数据缓存机制,将捕获的数据包缓存在内核中,达到一定数量后传递给应用程序。
BPF主要由网络转发和包过滤两部分组成。 网络转发部分从链路层捕获数据包并将它们转发给数据过滤部分。
数据包过滤部分从接收到的数据包中接收过滤规则确定的网络数据包,其他数据包被丢弃。
1.4 网络协议分析技术
协议分析的过程主要包括三部分:
1.4.1 捕获数据包
Libpcap ,Winpcap 等
1.4.2 过滤数据包
在内核层过滤:效率高 Libpcap
在应用层过滤:从内核层到应用层之间的转换费时费力
1.4.3 具体协议分析
链路层-〉网络层-〉传输层-〉应用层
Tcpdump,Windump,Ethereal 等
1.5 常用的网络开发包简介
在网络安全工具的开发中,最流行的 C API 库是 libnet、libpcap、libnids 和 libicmp。它允许网络开发者忽略网络底层细节的实现,而专注于程序本身特定功能的设计和开发。
1.5.1 libpcap
该库提供的C函数接口可用于需要捕获通过网络接口的数据包的系统开发(只要接口通过,目的地址不一定是本地的)。
1.5.2 WinPcap
WinPcap由三部分组成
a) NPF(Net Packet Filter): 它是一个虚拟设备驱动文件。
它用于过滤数据包并将它们未经修改地传递给用户区模块,包括过程中的一些特定于操作系统的代码。
b) packet.dll: 提供win32平台的通用接口。 不同版本的 Windows 系统都有自己的内核模块和用户级模块。
Packet.dll 用于解决这些差异。 调用 Packet.dll 的程序可以在不同版本的 Windows 上运行,无需重新编译
c) Wpcap.dll: 独立于操作系统。 它提供了更高级别的抽象。
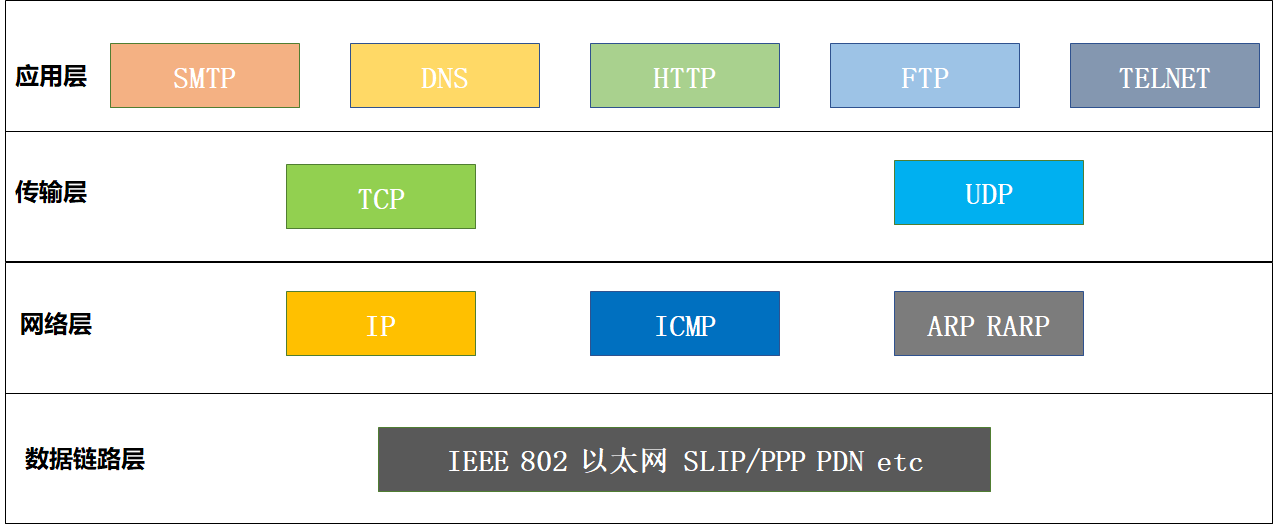
1.5.3 TCP/IP协议
1.5.4 构造并发送一个TCP包为例

第2章 网络信息获取-主动获取
2.1 介绍和概念
主动采集不需要辅助访问,只要客户端连接互联网就可以进行采集,数据处理可以离线进行,无需实时性能。 主动获取需要为信息获取而设计的爬虫程序。
主动信息收集我们可以通过主动与这些目标互动来收集有关这些目标的更多信息。 可以使用 DNS 枚举、端口扫描、操作系统指纹。主动获取不需要协作。 只需要知道网站的 url,因为网站是公开的,作为用户之一,并以一种许可的方式获取。
2.1.1 获取范围
主动获取的范围可以在任何地方,只要是在互联网上公开发布的,范围不限。比如:Web、论坛、博客、微信、P2P。
2.1.2 数据处理实时性
主动采集后可以在本地存在,后续分析可以在本地进行,对实时性要求不强。
2.1.3 技术指标
与单位时间获取的需求相匹配的有效内容;在网页抓取期间,它是网页托管服务器的开销,因此它应该不那么激进;信息获取应符合法律规定,否则可能产生法律后果。
2.1.4 技术难点
由于目标系统不断更新,因此应该很容易定制以适应目标系统。处理音频和视频等非文本信息。
2.2 网络爬虫
通用网络爬虫收集尽可能多的页面信息,在这个过程中它不太关心页面的顺序和页面的相关主题。这需要消耗大量的系统资源和网络带宽。聚焦爬虫尽可能快地爬取和摄取与预定义主题相关的尽可能多的网页。聚焦爬虫可以按主题收集整个Web,整合不同区块的收集结果。
2.2.1 爬取系统流程
2.3 网络信息搜索系统
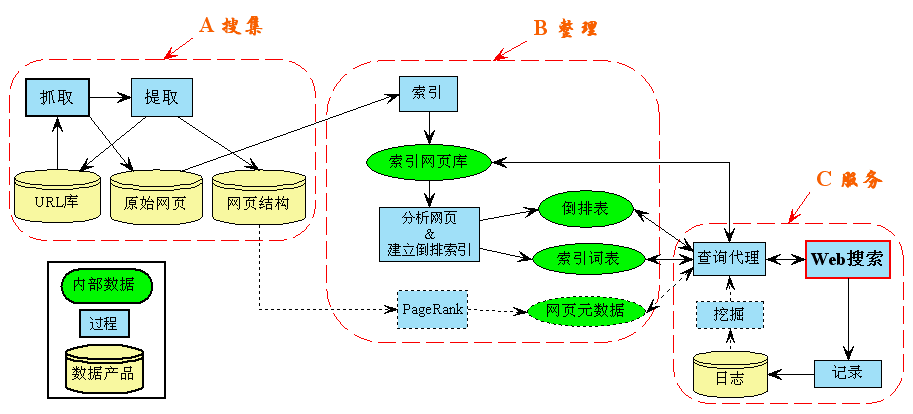
2.3.1搜索器
搜索器的功能是漫游互联网,发现和收集信息。 它需要尽可能快地收集各种类型的新信息。
同时,由于互联网上的信息更新速度很快,它也会定期更新已经收集到的旧信息,避免死连接和无效连接。
a) 网络爬虫抓取过程
1) 选择种子 URL 的一部分并将其放入队列中。
2) 取出URL,解析DNS,获取主机IP,下载并存入库。 此外,将这些URL放入爬网URL队列中。
3) 分析URL队列中已经爬取的URL,得到一个新的URL,进入下一个循环。
b) 单机爬取算法
DS:
Url_QUEUE uqueue;
History_LIST hlist;
PROCEDURE:
Crawler(seed_url) // seed_url是起始URL队列集合
{ in_queue (uqueue , seed_url);
while (u=out_queue(uqueue)) //从uqueue队列中移除url地址
{
wpage=http_get(u); // 下载网页
save wpage; // 保存网页
for each url in wpage // 解析网页中的URL,看是否被访问过
{ if url not in hlist
then in_queue (uqueue , url); } // 未被访问加入到uqueue队列中
}
}
c) 多机爬取算法
DS:
Url_QUEUE uqueue;
History_LIST hlist;
PROCEDURE:
Crawler(seed_url) // seed_url是起始URL队列集合
{ in_queue (uqueue , seed_url);
while (u=out_queue(uqueue) ) //从uqueue队列中移除url地址
{
wpage=http_get(u); // 下载网页
save wpage; // 保存网页
for each url in wpage // 解析网页中的URL,看是否被访问过
{ if url not in hlist
then {
n=hash(url ) mod N; // N为节点机总个数
if (n == my_node_ID)
then in_queue (uqueue , url);
// 将url发到节点机n,并插入到n的uqueue
else sendurl(url,n);
}
} // 未被访问加入到uqueue队列中
}
}
2.3.2 索引器
索引器的作用是了解搜索器搜索到的信息,从中提取索引项,用它来表示文档,生成文档库的索引表。
客观项与文档的语义内容无关,如作者姓名、URL、更新时间、编码、长度、链接流行度等;
内容索引项用于反映文档内容,如关键字及其权重、短语、词等; 内容索引条目可以分为单索引条目和多索引条目(或短语索引条目);
对于中文等连续书写的语言,需要分词。
链接流行度(Link Popularity): PageRank
PageRank 是 Google 算法的重要组成部分。每个指向页面的链接都是对该页面的投票,您获得的链接越多,您从其他网站获得的投票就越多。衡量有多少人愿意将他们的网站链接到您的网站。 意味着它被普遍认可和信任,那么它的排名很高。
算法基本思想
如果页面T有到页面A的链接,则表示T的所有者认为 A 更重要,因此将T的一部分重要性分数分配给A。这个重要性分数为:
PR(T)/C(T)
其中,PR(T)为T的PageRank值,C(T)为T的外部链接数; A的PageRank值是一系列类似于T的页面重要性分数的累加。
2.3.3 检索器
检索器的作用是根据用户查询快速检测索引数据库中的文档,评估文档与查询的相关性,对输出结果进行排序,实现用户相关性反馈机制。
检索器常用的信息检索模型有四种:集合论模型、代数模型、概率模型和混合模型。
2.3.4 用户接口
用户界面的作用是输入用户查询,显示查询结果,提供用户相关性反馈机制。
主要目的是为了方便用户使用搜索引擎,以高效、多渠道的方式从搜索引擎获取有效及时的信息。
2.4 网页搜索策略
根据一定的网页分析算法过滤掉不相关的链接,保留有用的链接,放入待抓取的URL队列中。 爬虫爬取到的所有网页都会被系统存储起来,经过一定的分析、过滤、索引,以供后续查询和检索。
2.4.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个链接,处理完这一行后,再到下一个起始页,继续跟踪链接。
2.4.2 广度优先遍历策略
将在新下载的网页中找到的链接直接插入到要抓取的URL队列的末尾。
首先爬取起始页中链接的所有页面,然后选择其中一个链接页面继续爬取该页面中链接的所有页面。
2.4.3 最佳优先搜索策略
根据某种网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL进行爬取。
它只访问页面分析算法预测为“有用”的页面。
第3章 字符串匹配
3.1 介绍和概念
字符串匹配是在给定的字符流中找到满足某些指定属性的字符串。 它也称为模式匹配。用于生物计算领域的字符串匹配,用于匹配或比较两个基因序列之间的DNA链;在信号处理领域,语音识别用于判断语音信号是否符合某些特征;在信息检索中,IR(Information Retrieval)需要在大量的文本集合中寻找相关信息;在网络安全领域,快速发现具有一定特征的有害信息,尽快杜绝其发生。
3.1.1 概念
1.文本: 有限的字符序列,\(y = \{y_{1}y_{2}y_{3}\ldots y_{n}\}\),其中 \(n\)
是文本长度。
2.模式: 字符的有限序列, \(k = \{ k_{1}k_{2}k_{3}\ldots k_{m}\}\),其中 \(m\)
是模式长度。
3.模式集: 所有需要匹配的模式组成的集合,记为 \(P = \{p_{1},p_{2},\ldots,p_{r}\}\),其中
\(p_{i}\) 是模式集中的第 \(i\) 个模式。
4.最小模式长度: 在模式集中具有 \(l_{1}l_{2}l_{3}\ldots l_{r}\) 长度。
最小模式长度是所有模式长度中的最小值,即 \(minlen = min \{l_{1},l_{2},l_{3},\ldots,l_{r}\}\)。
5.前缀: \(p = xv\) 成立,\(x\) 称为 \(p\) 的前缀,(\(v\) 可以是空字符串)
6.后缀: \(p = ux\) 成立,\(x\) 称为 \(p\) 的后缀,(\(u\) 可以是空字符串)
7.子串: \(p = uxx\) 成立,称 \(x\) 为 \(p\) 的子串,(\(u,v\) 可以为空串)
8.字符集: 由模式或文本中所有可能的字符组成的集合 \(\Sigma\) 记为 ,其大小记为 \(|\Sigma|\)。
9.自动机(Automata):(DFA) 五元组 \(M = \{ S,\Sigma,\delta,s_{0},S_{1}\}\) 包括状态集 \(S\)、输入字符集 \(\Sigma\) 、状态转移函数 \(\delta\)、起始状态 \(s_{0}\) 和结束状态集 \(S_{1}\)。
3.2 模式匹配算法
3.2.1 单模式匹配算法
在一个文本text(设长度为n)中查找某个特定的子串pattern(设长度为m)。如果在text中找到等于pattern的子串,则称匹配成功,函数返回pattern在text中出现的位置(或序号),否则匹配失败。
比如: BF算法, KMP算法, BM算法,等
3.2.2 多模式匹配算法
在一个文本text(设长度为n)中查找某些特定的子串patterns(设长度为m)。如果在text中找到等于patterns中的某些子串,则称匹配成功,函数返回pattern在text中出现的位置(或序号),否则匹配失败。
比如: AC算法, Wu-Manber算法,等
3.3 Brute-Force (BF) 算法
3.3.1 主要思想
从左向右,依次比较,每次移动一个字符位置。比较方向可以任意选定。无预处理阶段。
3.3.2 算法
输入: 文本数组 \(T[0…n-1]\) 文本,模式数组 \(P[0…m-1]\)
输出: 匹配字符串中第一个字符的索引,如果不匹配,则为 -1
方法:
BruteForceMatch(T[n], P[m])
for i←0 to n-m do
j←0
while j<m and P[j]=T[i+j] do
j←j+1
if j=m return i
return -1
时间复杂度: \(O(mn)\)
3.4 Knuth-Morris-Pratt (KMP) 算法
3.4.1 主要思想
KMP(D.E. Knuth, J.H.Morris, and V.R.Pratt)主要是基于对BF算法的改进:BF算法只是简单的每次移动一个字符位置,并没有考虑已匹配成功部分的信息。其实这些信息是可以利用的,此即所谓的“前缀模式”—-模式中不同部分存在的相同子串。
3.4.2 算法
输入: 文本数组 \(T[0…n-1]\) 文本,模式数组 \(P[0…m-1]\)
输出: 所有数字的列表,使得 P 在 T 中出现移位
方法:
Compute-Prefix-Function(P[m])
m ← length(P)
π[1] ← 0
k ← 0
for q ← 2 to m do
while k > 0 and P[k+1] != P[q] do
k ← π[k]
if P[k+1] = P[q] then
k ← k + 1
π[q] ← k
return π
KMP-Matcher(T[n], P[m])
n ← T.length
m ← P.length
π ← Compute-Prefix-Function(P)
q ← 0 // num of characters matched
for i ← 1 to n do // scan text T from left to right
while q > 0 and P[q+1] != T[i] do
q ← π[q] // next characters does not match
if P[q+1] = T[i] then
q ← q + 1 // next characters matches
if q = m then // is all of P matched
print "Pattern occurs with shift" i - m
q ← π[q] // look for the next match
时间复杂度:\(O(m + n)\)
3.5 Boyer-Moore (BM) 算法
3.5.1 主要思想
算法从正文左端开始扫描,对齐后从模式最右端开始自右向左诸字符比较。在不匹配(或完全匹配)时,用两个预先计算的函数bad character和good suffix 来确定指针在正文中移动的距离。
3.5.2 算法
输入: 文本数组 \(T[0…n-1]\) 文本,模式数组 \(P[0…m-1]\)
输出: 所有数字的列表,使得 P 在 T 中出现移位
方法:
COMPUTE-LAST-OCCURRENCE-FUNCTION (P, m, ∑)
for each character a ∈ ∑
λ[a] = 0 do
for j ← 1 to m do
λ[P [j]] ← j
return λ
COMPUTE-GOOD-SUFFIX-FUNCTION (P, m)
Π ← COMPUTE-PREFIX-FUNCTION (P)
P1 ← reverse (P)
Π1 ← COMPUTE-PREFIX-FUNCTION (P1)
for j ← 0 to m do
ɣ [j] ← m - Π [m]
for l ← 1 to m do
j ← m - Π1[L]
if ɣ [j] > l - Π1[L] then
ɣ [j] ← 1 - Π1[L]
return ɣ
BOYER-MOORE-MATCHER (T, P, ∑)
n ← T.length
m ← P.length
λ ← COMPUTE-LAST-OCCURRENCE-FUNCTION (P, m, ∑)
ɣ ← COMPUTE-GOOD-SUFFIX-FUNCTION (P, m)
s ← 0
while s ≤ n - m do
j ← m
while j > 0 and P [j] = T [s + j] do
j ← j - 1
if j = 0 then
print "Pattern occurs at shift" s
s ← s + ɣ[0]
else s ← s + max (ɣ [j], j - λ[T[s+j]])
时间复杂度:\(O(mn)\)
3.6 Aho-Corasick (AC) 算法
3.6.1 主要思想
Aho-Corasick自动机算法(简称AC自动机)1975年产生于贝尔实验室。该算法应用有限自动机巧妙地将字符比较转化为了状态转移。
该算法的基本思想是这样的:
在预处理阶段,AC自动机算法建立了三个函数,转向函数goto,失效函数failure和输出函数output,由此构造了一个树型有限自动机。
在搜索查找阶段,则通过这三个函数的交叉使用扫描文本,定位出关键字在文本中的所有出现位置。
3.6.2 算法
算法1: 树型有限状态机
输入: 一个文本正文 \(Y = \{ y_{1}y_{2}y_{3}\ldots y_{n}\}\) (其中 \(y_{i}\) 是一个输入字符);一台包含上述转向函数g,失效函数f和输出函数output的树型有限自动机;
输出: 关键字在y中出现的位置
方法:
begin
state ← 0
for i ← 1 until n do
begin
while g(state, ai) = fail do state ← f(state)
state ← g(state, ai)
if output(state) ≠ empty then
begin
print i
print output(state)
end
end
end
算法2: 建立转向函数g
输入: 关键字集 \(Y = \{ y_{1},y_{2},y_{3},\ldots y_{n}\}\)
输出: 转向函数g和部分的output函数
方法: 我们假设第一次创建状态s时输出为空,如果g(s,a)未定义或尚未定义,则g(s,a)=fail。过程enter(y)将拼写为y的路径插入到goto图中。
begin
newstate ← 0
for i ← 1 until k do enter(yi)
for all a such that g(0, a) = fail do g(0, a) ← 0
end
Procedure enter(a1a2…am)
begin
state ← 0; j ← 1
while g(state, aj) != fail do
begin
state ← g(state, aj)
j ← j + 1
end
for p ← j until m do
begin
newstate ← newstate + 1
g(state, ap) ← newstate
state ← newstate
end
output(state) ← {a1a2…am}
end
算法3: 建立失效函数f
输入: 转向函数g和部分的输出函数output
输出: 失效函数f和完整的输出函数output
方法:
begin
queue ← empty
for each a such that g(0, a) = s ≠ 0 do
begin
queue ← queue ∪ {s}
f(s) ← 0
end
while queue ≠ empty do
begin
let r be the next state in queue
queue ← queue - {r}
for each a such that g(r, a) = s ≠ fail do
begin
queue ← queue ∪ {s}
state ← f(r)
while g(state, a) = fail do state ← f(state)
f(s) ← g(state, a)
output(s) ← output(s) ∪ output(f(s))
end
end
end
时间复杂度:\(O(n)\)
3.7 Wu-Manber算法
3.7.1 主要思想
Wu-Manber算法是1992年台湾学者吴升发明,是模式中最为著名的快速匹配算法之一,采用了跳跃不可能匹配的字符策略和hash散列的方法,对处理大规模的多关键字匹配问题有很好的效果。
在预处理阶段,算法主要使用了三个数据结构:SHIFT表、HASH表、和PREFIX表。在搜索查找阶段,SHIFT表用于在扫描文本串的时候,根据读入字符串决定可以跳过的字符数,如果相应的跳跃值为0,则说明可能产生匹配,就要用到HASH表和PREFIX表进一步判断,以决定有哪些匹配候选模式,并验证究竟是哪个或者哪些候选模式完全匹配。
3.7.2 算法
输入: 文本T和模式列表P
输出: 与文本中的模式匹配的位置
方法:
WuManber(P = {p1, p2, ... , pr}, T = t1t2... tn)
//Preprocessing
Compute a suitable value of B (e.g. B = logc2M)
Construct tables SHIFT and HASH;
// Searching
pos = min;
while pos ≤ n do
i = h1(tpos – B + 1... tpos);
if SHIFT[i] = 0 then
list = HASH[h2(tpos – B + 1... tpos)];
Verify all patterns in list against the text;
pos++;
else
pos = pos + SHIFT[i];
时间复杂度: \(O(B*n/m)\)
第4章 文本分类
4.1 介绍
高效成熟的文本自动分类技术在特定信息内容识别、舆情分析、搜索引擎、自动信息抽取、用户信息过滤等领域具有广阔的应用前景。暴力、邪教、分裂、贪污、黄赌毒、侵权、隐私泄露等内容识别;垃圾邮件过滤:类别{垃圾邮件,非垃圾邮件};舆情分析:热点话题追踪;网页分类:类似于雅虎的分类;开源情报分析
4.1.1 文本分类
文本分类是将数据分成预先定义好的类别,一般流程为:
- 预处理,比如分词,去掉停用词;
- 文本表示及特征选择;
- 分类器构造;
- 分类器根据文本的特征进行分类;
- 分类结果的评价。
4.2 文本表示
4.2.1 One-hot
One-hot方法将每一个单词使用一个离散的向量表示,将每个字/词编码成一个索引,然后根据索引进行赋值。
n维稀疏向量,向量中一位为1,其余为0。
句子1:我 爱 北 京 天 安 门
句子2:我 喜 欢 上 海
首先索引所有句子的单词,即为每个单词确定一个数字:
{'我': 1, '爱': 2, '北': 3, '京': 4, '天': 5,
'安': 6, '门': 7, '喜': 8, '欢': 9, '上': 10, '海': 11}
一共11个词,转换为11维稀疏向量:
我: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
爱: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
...
海: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
4.2.2 Bags of words
一袋词意味着,也称为计数向量,可以表示每个文档中某个词的出现次数。
计算出现次数并根据索引分配:
句子1:我 爱 北 京 天 安 门
转换为 [1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0]
句子2:我 喜 欢 上 海
转换为 [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]
4.2.3 N-gram
N-gram 与 Count Vector 类似,只是将相邻的单词组合添加为新单词并进行计数。
如果 N 为 2,则句子变为:
句子1:我爱 爱北 北京 京天 天安 安门
句子2:我喜 喜欢 欢上 上海
4.2.4 TF-IDF
TF-IDF通过比较单词在文档中出现的次数和单词在文档中出现的次数来衡量单词的原创性。 TF:Term Frequency 词语频率;
IDF:Inverse Document Frequency 逆文档频率;
\(TF(t) = \left( \frac{该词语在当前文档出现的次数\ }{当前文档中词语的总数} \right)\)
\(IDF(t) = \log\left( \frac{文档总数\ }{1 + 出现该词语的文档总数} \right)\)
4.3 基于规则的分类
4.3.1 C2
CN2是一个规则生成工具工具,它通过学习大量已知属性的实例生成规则作为分类依据,便于根据规则对输入的未知属性进行分类和评估。
当将大量样本放在一起进行分类比较时,分类必然存在异同,而这些异同是由样本中的特征值造成的。一些特征的定值组合可以作为分类。
4.3.2 C4.5
C4.5是一种决策树算法。
决策树算法的目标是将具有p维特征的n个样本分类为c个类别。通过转换为样本分配类标签。决策树可以将分类过程表示为一棵树,并通过每次选择一个特征pi对其进行分叉。
4.4 朴素贝叶斯(Naive Bayes)分类器
朴素贝叶斯分类器是基于贝叶斯理论的分类器。 它的特点是以概率的形式表达各种形式的不确定性,学习和推理是通过概率规则来实现的,学习的结果可以解释为对不同可能性的信任程度。
\[P\left( H \middle| X \right) = \frac{P\left( X \middle| H \right)\ P(H)}{P(X)} = \frac{P\left( X \middle| H \right)\ P(H)}{\sum_{H}^{}{P\left( H \right)\ P(X|H)}}\]P(H)是先验概率,或H的先验概率。 P(H|X) 是后验概率,或条件X下,H的后验概率。后验概率 P(H|X) 比先验概率P(H)基于更多的信息。P(H)是独立于X的。
4.5 支持向量机(Support Vector Machine)
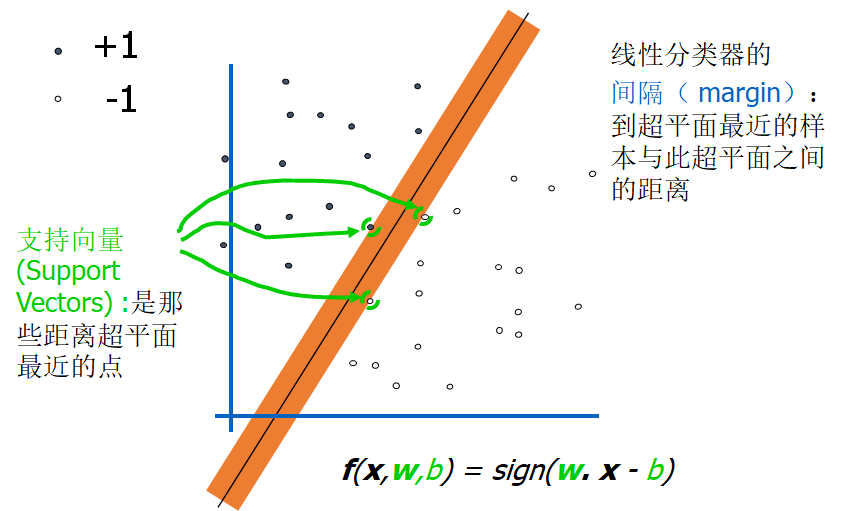
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。SVM使用损失函数(hinge loss)计算经验风险(empirical risk)并加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。
4.6 K-最近邻分类
K-最近邻(K-NN)分类基于监督学习技术。 在给定的待分类样本中,考虑与训练样本集中待分类样本最接近(最相似)的K个样本。待分类样本的类别根据K个样本中大部分属于哪个类别来确定。 K-NN算法的优点是准确度高。研究表明,K-NN的分类效果明显优于朴素贝叶斯分类和决策树分类。
4.6.1 算法
一、以向量空间模型的形式描述各训练样本。
二、在全部训练样本集中选出与待分类样本最相似的K个样本。K值的确定目前没有很好的方法,一般采用先定一个100左右的初始值,然后再调整。
三、将待分类样本标记为其K个邻居中所属最多的那个类别中。
欧氏距离: \(d\left( x,y \right) ≔ \sqrt{\left( x_{1} - y_{1} \right)^{2} + \left( x_{2} - y_{2} \right)^{2} + \ldots + \left( x_{n} - y_{n} \right)^{2}} = \sqrt{\sum_{i = 1}^{n}\left( x_{i} - y_{i} \right)^{2}}\)
4.7 基于密度的聚类
只要半径为r的相邻区域的密度超过某个阈值p,聚类就会继续。 避免只生成球形簇。(DBSCAN、OPTICS、DENCLUE)
4.7.1 DBSCAN算法
输入: D := 一个包含n个对象的数据集;ε:= 半径参数; MinPts: 邻域密度阀值
输出: 基于密度的聚的集合
方法:
标记所有对象为 unvisited;
Do
随机选择一个 unvisited 对象p;
标记 p 为 visited;
If p 的 ε -邻域至少有 MinPts 个对象
创建一个新簇 C, 并把 p 添加到 C;
令 N 为 p 的 ε -邻域中的对象集合;
For N 中每一个点 p1
If p1 是 unvisited;
标记 p1 为visited;
If p1 的 ε -邻域至少有 MinPts 个对象,
把这些对象添加到N中;
If p1 还不是任何簇的成员, 把 p1 添加到C;
End for;
输出C;
Else 标记 p 为噪声点;
Until 没有标记为 unvisited 的对象;
4.8 基于层次的聚类
生成一组嵌套集群,组织为层次树。凝聚法是指最初将每个样本点视为一个簇,因此原始簇的大小等于样本点的个数,然后将这些初始簇按照一定的标准进行合并,直到达到某个条件或达到设定点。
4.8.1 算法
输入: 样本集合D,聚类数目或者某个条件(一般是样本距离的阈值,这样就可不设置聚类数目)
输出: 聚类结果
方法:
1.将样本集中的所有的样本点都当做一个独立的类簇;
repeat:
2.计算两两类簇之间的距离(后边会做介绍),找到距离最小的两个类簇c1和c2;
3.合并类簇c1和c2为一个类簇;
util: 达到聚类的数目或者达到设定的条件
4.9 K-均值算法
K-均值算法是一种无监督学习算法,它将未标记的数据集分组到不同的集群中。 这里K定义了流程中需要创建的预定义簇的数量,如果K=2,就会有两个簇,如果K=3,就会有三个簇,以此类推。
4.9.1 算法
begin initialize 样本数n, 聚类数c, 初始聚类中心m1, …, mc;
do 按照最邻近mi分类n个样本;
重新计算聚类中心m1, …, mc;
until {mi} 不再改变;
return m1, …, mc;
end
4.10 Web挖掘
Web 是非结构化和动态的,Web 页面比文本文档复杂得多。 信息极其丰富而知识相对稀缺,就是所谓的“信息爆炸”问题。 因此,大量异构Web信息资源中蕴含的具有巨大潜在价值的知识,使得人们迫切需要能够快速有效地从Web中发现资源和知识的工具。
4.10.1 概念
定义: Web挖掘是指从大量Web文档的集合 \(W\) 中发现隐含的模式 \(p\)。如果将 \(W\) 看作输入,将 \(p\)看作输出,那么Web挖掘的过程就是从输入到输出的一个映射 \(\xi\ :\ W \rightarrow p\)
它描述了Web挖掘的通用模型。文档集W是一些网页的集合,这些网页的结构用HTML、Java或Vbscript等语言描述,内容用简体中文GB2312、Unicode或西欧字符ISO表示。模式E是可用于描述一组文档W的子集WE的表达式、图形或结构。作为模式的E要求它比数据子集WE的枚举更简单。
第5章 P2P安全管理
5.1 P2P起源
Napster由18岁的Shawn Fanning使用P2P技术于1999年创立。任何拥有CD的人都可以将他们的收藏放在网上,与他人交换并下载。
定义1: P2P是一种分布式网络,网络中的参与者共享自己的一部分硬件资源(处理能力、存储能力、网络连接能力、打印机等)。其他对等节点(Peers)直接访问,无需经过中间实体。该网络的参与者既是资源(服务和内容)提供者(服务器),又是资源(服务和内容)获取者(客户)。
定义2: 2009年,IEEE-P2P会议第一次在欧洲以外的地区召开—
—美国的西雅图市,其组织者将P2p定义为“覆盖网络技术和大 规模并行系统及应用”,广义的延伸为“任何以分散化和资源共享为特征的大规模分布式系统”
5.2 P2P系统的分类
- 提供文件和其它内容共享的P2P网络,例如Napster、Gnutella、eDonkey、emule、BT;
- 挖掘P2P对等计算能力和存储共享能力,例如SETI@home、Avaki、Popular Power;
- 基于P2P方式的协同处理与服务共享平台,例如JXTA、Magi、Groove、.NET My Service;
- 即时通讯交流,包括ICQ、OICQ、Yahoo Messenger;
- 安全的P2P通讯与信息共享,例如Skype、Crowds、Onion Routing。
5.3 P2P结构分类
- 非结构化P2P
网络拓扑是任意的。 无论网络拓扑如何,都存储内容。 - 结构化P2P
网络拓扑规则。 每个节点随机生成一个标识(ID)。 内容的存储位置与网络拓扑有关。 内容的存储位置与节点标识之间存在映射关系。 - 完全分布式的P2P网络
在没有中心节点的情况下,对等节点泛洪网络以找到与密钥对应的值。 在对等点之间建立直接连接以下载内容。 - 基于目录服务器的P2P网络
所有对等点都将其索引发布到目录服务器。 peer通过目录服务器查找key对应的value。 在对等点之间建立直接连接以下载内容。 - 层次P2P网络
对等节点根据是否具备足够的计算和存储能力、是否有公网IP等不同的能力分为超级节点和通用节点。 超级节点之间形成一个完全分布式的 P2P网络。 超级节点和与其相连的通用节点组成一个基于目录服务器的P2P网络,其中超级节点具有目录服务器的功能。
5.4 基于分布式Hash表 (DHT)
单向散列函数也称为散列函数。 根据给定的任意长消息段计算出一个固定长度的比特串,通常称为消息摘要(MD:Message Digest)。在哈希函数中,对于给定的消息M,很容易计算出消息摘要MD(M)。
但是对于只给定消息摘要MD(M),几乎不可能找到消息M。 常用的散列函数有MD5:任意长度的消息,消息摘要128位; SHA-1:任意长度的消息,消息摘要160位。
5.4.1 过程
- \(<K, V>\) 对的抽象内容索引
K是内容关键字的哈希摘要
\(K = Hash(key)\)
V为内容实际存放的位置,如节点IP地址等。 - 所有的 \(<K, V>\) 对组成一个大的Hash表,所以这个表存储了所有的信息。
- 每个节点随机生成一个ID,将Hash表分成许多小块,按照特定的规则(即K与节点ID的映射关系)分发到网络中,节点在应用层按照 这个规则。
形成结构化的重叠网络。 - 查询内容的K值,根据K与节点ID的映射关系,可以在重叠网络上找到对应的V值,从而得到存储文件的节点的IP地址。
5.5 Chord-Hash 表分布式规则
5.5.1 格式
| Hash算法SHA-1 Hash节点IP地址 → m位节点 ID (表示为NID) Hash内容关键字 → m位 K (表示为KID) 节点按ID从小到大顺序排列在一个逻辑环上 <K, V> 存储在后继节点上 Successor(K):从K开始顺 时针方向距离K最近的节点 |
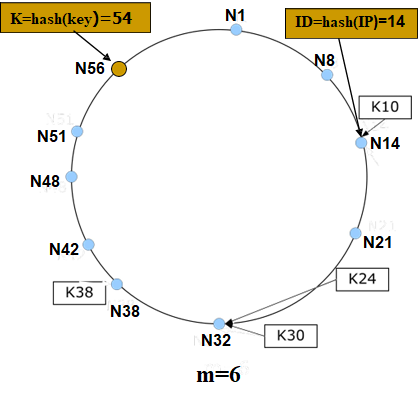 |
5.5.2 过程
- 每个节点只维护其后继节点ID、IP地址等信息。
- 查询消息通过后继节点指针在环上传递。
- 直到查询消息中包含的K落在节点ID与其后继节点ID之间。
- 速度非常慢O(N),其中N是网络中的节点数。
5.6 针对P2P系统的管理手段
5.6.1 P2P技术给内容安全带来的挑战
传统的C/S通信方式被动监控方式具有控制精度高、成功率高、见效快、易于部署等优点,但应用于P2P系统时,只能解决局部问题。
信息源分布广泛、传播速度快、难以集中控制,对敏感信息的定位、监控和控制提出了新的挑战。
5.6.2 索引污染
特点是恶意节点向网络注入大量虚假索引,欺骗用户下载。 此类攻击可分为两种方式,
(1) 索引毒害: 文件索引提供与热文件和不存在的文件源相同的文件描述信息,使用户难以找到真正的热文件;
(2) 索引污染: 文件内容通过虚假索引指向恶意节点的虚假文件;如果用户下载后不及时查看,可能会导致假文件继续被分享,导致网络上出现大量假副本。
5.6.3 资源占用
在共享网络形成之前,种子节点很少,文件块分布不均。 此时对种子节点的资源占用攻击可以杀死共享网络。
(1) 带宽占用: 请求大量数据,占用种子节点上传带宽;
(2) 连接占用: 不请求数据,但与种子节点保持应用层TCP连接,使种子节点的TCP连接数达到上限。
5.6.4 数据欺骗
大多数P2P软件的选择策略是使用Local Rarest First (LRF)。数据欺骗是指可控节点没有某些数据块,但声称拥有并允许其他节点下载其他块,导致恶意节点声称的块被任何人下载,直到它们消失,共享网络失败。
5.6.5 数据块污染
分片不验证,只验证块以减少验证次数。 攻击者谎称自己拥有所有区块并诱导其他节点下载,而提供给下载者的区块是虚假的。当下载者完成区块下载后,验证必然失败,因此整个区块的下载失败。块污染攻击可以显着降低节点下载速度。
5.6.6 其他方法
1) Eclipse 方法:
目的是将共享网络划分为两个或多个区域,使这些划分区域的通信能够被恶意节点掌握,最终整个网络可能完全停止运行。
2) Sybil 方法:
P2P 需要大量的勾结节点。 主机通过伪造多个合法用户加入网络。
由于P2P系统是匿名开发的,对用户的访问控制不严格,所以这种方法很容易实现。
第6章 数据隐私保护
6.1 介绍
数据隐私是数据保护的一个领域,涉及正确处理敏感数据,尤其是个人数据,以及其他机密数据,例如某些财务数据和知识产权数据,以满足监管要求并保护数据的机密性和不变性。 数据隐私定义了谁可以访问数据,而数据保护提供了工具和策略来实际限制对数据的访问。 数据保护是一组可用于保护数据隐私、可用性和完整性的策略和流程。有时也称为数据安全。
6.2 欧盟隐私保护新规正式生效(GDPR)
通用数据保护条例(EU)(GDPR)是欧盟法律中关于欧盟(EU)和欧洲经济区(EEA)数据保护和隐私的条例。GDPR是欧盟隐私法和人权法的重要组成部分,尤其是《欧盟基本权利宪章》第8条第1款。它还解决了欧盟和欧洲经济区以外的个人数据传输问题。GDPR明确并加强了现有的个人权利,例如删除个人数据的权利和要求公司提供数据副本的权利。GDPR于2016年4月14日通过,并于2018年5月25日开始执行。
GDPR2016共有十一章,涉及一般规定、原则、数据主体的权利、数据控制者或处理者的职责、向第三国转移个人数据、监管机构、成员国之间的合作、补救措施、责任或处罚违反权利和其他最终条款。
GDPR提高了违反隐私法的罚款金额,违反法律的公司将被处以高达其收入2-4%或10-2000万欧元的罚款。
6.3 加州消费者隐私法案(CCPA)
加利福尼亚州消费者隐私法(CCPA)是一项旨在加强美国加利福尼亚州居民隐私权和消费者保护的州法规。
CCPA包括以下四点特点:
- 适用范围及调整对象十分广泛;
- 法案确立了消费者信息处理基本规则;
- 法案赋予消费者更大的信息控制权;
- 提供可明确且具备可执行性的救济措施。
6.4 中华人民共和国个人信息保护法
第一种是过度收集个人信息。
第二种是擅自披露个人信息。
第三种是擅自提供个人信息。
第六条 各地区、各部门对本地区、本部门工作中收集和产生的数据及数据安全负责。
第七条 国家保护个人、组织与数据有关的权益,鼓励数据依法合理有效利用,保障数据依法有序自由流动,促进以数据为关键要素的数字经济发展。
第八条 开展数据处理活动,应当遵守法律、法规,尊重社会公德和伦理,遵守商业道德和职业道德,诚实守信,履行数据安全保护义务,承担社会责任,不得危害国家安全、公共利益,不得损害个人、组织的合法权益。
6.4.1 第二章 数据安全与发展
第十三条 国家统筹发展和安全,坚持以数据开发利用和产业发展促进数据安全,以数据安全保障数据开发利用和产业发展。
第十五条 国家支持开发利用数据提升公共服务的智能化水平。提供智能化公共服务,应当充分考虑老年人、残疾人的需求,避免对老年人、残疾人的日常生活造成障碍。
第十六条 国家支持数据开发利用和数据安全技术研究,鼓励数据开发利用和数据安全等领域的技术推广和商业创新,培育、发展数据开发利用和数据安全产品、产业体系。
第十九条 国家建立健全数据交易管理制度,规范数据交易行为,培育数据交易市场。
第二十条 国家支持教育、科研机构和企业等开展数据开发利用技术和数据安全相关教育和培训,采取多种方式培养数据开发利用技术和数据安全专业人才,促进人才交流。
6.4.2 第三章 数据安全制度
第二十一条 国家建立数据分类分级保护制度,根据数据在经济社会发展中的重要程度,以及一旦遭到篡改、破坏、泄露或者非法获取、非法利用,对国家安全、公共利益或者个人、组织合法权益造成的危害程度,对数据实行分类分级保护。国家数据安全工作协调机制统筹协调有关部门制定重要数据目录,加强对重要数据的保护。
第二十四条 国家建立数据安全审查制度,对影响或者可能影响国家安全的数据处理活动进行国家安全审查。
第二十五条 国家对与维护国家安全和利益、履行国际义务相关的属于管制物项的数据依法实施出口管制。
6.5 隐私保护数据发布(PPDP)
6.5.1 数据和行为隐私保护
A.变换
1) 数据加密:以一定的规则对数据进行变换,只有授权用户才能还原真实数据。
2) 同态加密(Homomorphic encryption)对经过同态加密的数据进行处理得到一个输出,将这一输出进行解密,其结果与用同一方法处理来加密的原始数据得到的输出结果是一样的。
3) 密文检索:它能够在信息资源加密存储的前提下,通过对其构建密文全文索引,提供高效安全的检索方法。
B.分治
1) 数据分割:通过将准标识符属性集进行垂直分割,割裂其中的关联关系,使得以对数据做笛卡尔积的方式还原数据的精度不高于1/k。
2) 分权机制:在相关实体间引入分权机制防止系统中 “超级” 节点的形成。基于分治的思路解决大数据隐私保护问题,核心是访问控制,否则难以对抗关联分析、背景知识挖掘等大数据时代的利器
C.隐匿
1) 匿名:在数据发布时,隐匿用户ID的指示信息。
2) 假名:在数据发布时,以假名代替用户的真实ID。
3) 基于众包(Crowdsourcing)的轨迹隐私保护: 利用传统的LBS服务中的Mix-Zone模型,利用二分图的理论实现假名交换以保护用户的轨迹隐私。
D.混淆
1) 数据泛化: 当数据中所包含的相同属性值的记录个数少于隐私要求时。
2) 数据加噪: 在原始数据中以一定的策略加入一些噪声数据以满足用户的隐私要求。
3) 位置模糊化:以一块空间区间区域代替用户的真实位置。
4) 隐私信息检索 PIR (privacy information Retrieval):将用户的查询请求通过一个矩阵变换构造出N-1个与其不可区分的伪查询,使得攻击者无法精确的知道用户的真实意图。
6.5.2 位置隐私保护
1) 基于空间匿名的位置隐私保护。
位置模糊:在一定程度上降低用户位置的精度以满足用户的隐私需求。
位置随机化:在原始位置数据中以一定都策略加入一些噪声信息。
2) 基于加密的位置隐私保护。 用户可以在不泄露位置信息的情况下检索服务器上的任意服务项。
3) 基于用户实体匿名的位置隐私保护。
匿名:在用户的查询请求中去除用户的ID。
参考
- 涛. 刘文. (2005). 网络安全开发包详解. 电子工业出版社.
- Navarro, G., &; Raffinot, M. (2014). Flexible pattern matching in strings: Practical on-line search algorithms for texts and biological sequences. Cambridge University Press.
- Cormen, Thomas; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001). “Section 32.4: The Knuth-Morris-Pratt algorithm”. Introduction to Algorithms (Second ed.). MIT Press and McGraw-Hill. pp. 923–931.
- Boyer, R. and Moore, J., 1977. A fast string searching algorithm. Communications of the ACM, 20(10), pp.762-772.
- Aho, A. and Corasick, M., 1975. Efficient string matching. Communications of the ACM, 18(6), pp.333-340.
- Wu, S., Manber, U. 1994. A fast algorithm for multi-pattern searching. Technical report TR94-17. University of Arizona at Tuscon
- Berry, M. W., &; Kogan, J. (2010). Text mining: Applications and theory. Wiley.
- 张宏莉,叶麟, & 史建焘 (2017). P2P 网络测量与分析. 人民邮电出版社
 P2P的: From Program to Process - CS大作业论文
P2P的: From Program to Process - CS大作业论文